Relators
Relators tie together – or relate – the other three basic building block namely Rules, Alerts, and Monitoring Groups
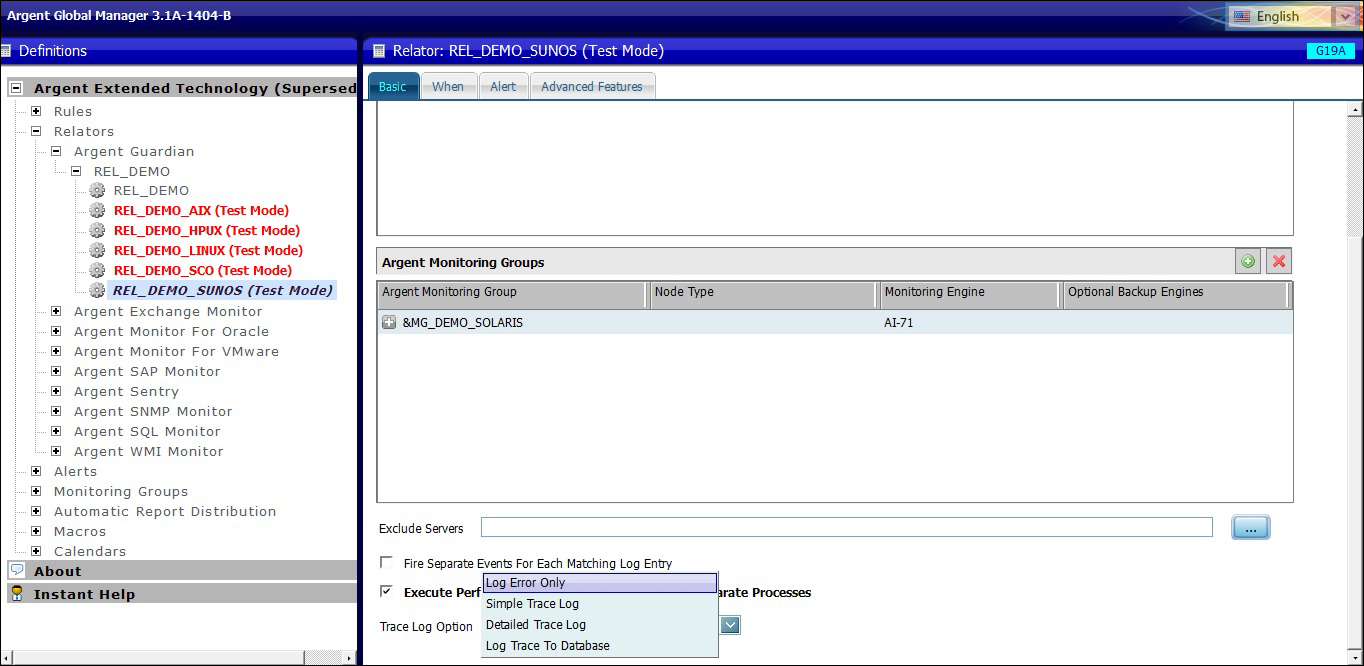
In a Relator the Rule to be executed against the servers and devices in the Monitoring Groups are specified
Also specified are the Alerts fired when an issue is detected
The benefit of a Relator is Rules, Alerts, and Monitoring Groups are all shared
Each Relator has its own monitoring rate — the frequency in minutes or seconds the Relator executes to check the servers and devices in the Monitoring Group
Each server and device is checked independently of the others — the results of checking one server or device in the Monitoring Group in no way affects the results of checking other servers or devices
Relators can also optionally use calendars
Argent calendars are derived from, and shared with, the Argent Job Scheduler
Thus any complex calendar can easily be created
For example, a common use of the Argent Calendar feature is the ability to run Relators on the second-last week of the quarter to check there are sufficient resources (such as free disk space) to correctly perform all End-Of-Quarter processing
All Relators are initially defined in Test mode – this prevents a Relator from starting prematurely
Relators have an optional Trace Log enabling testing and debugging of the Relator before it is put into production