KBI 311119 New Feature: Fire Urgent Group Alert When All Nodes In Monitoring Group Are Broken For The Same Rule
Version
Argent Advanced Technology 3.1A-1410-A And Later
Date
Monday, 17 Nov 2014
Summary
The new feature allows firing conditional alerts when all Nodes in the selected Monitoring Group are broken for the same Rule
This is extremely useful to monitor critical applications or clustered resources
For example, a web farm may span over a few IIS servers
If some of the web servers are offline, website may be less responsive, but it is still available
If all web servers are offline, the website will be completely down
It is straightforward to define such an Urgent Group Alert
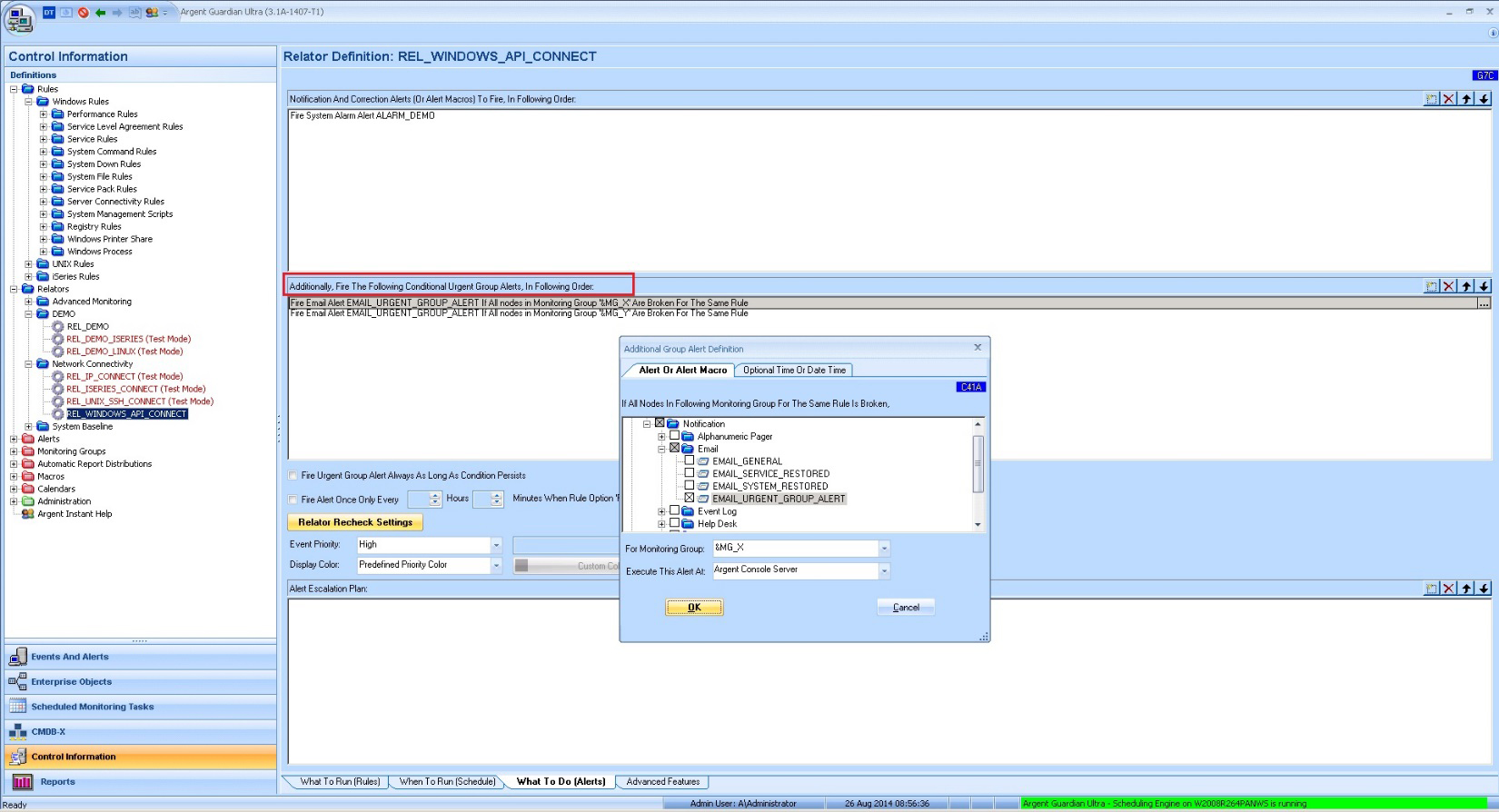
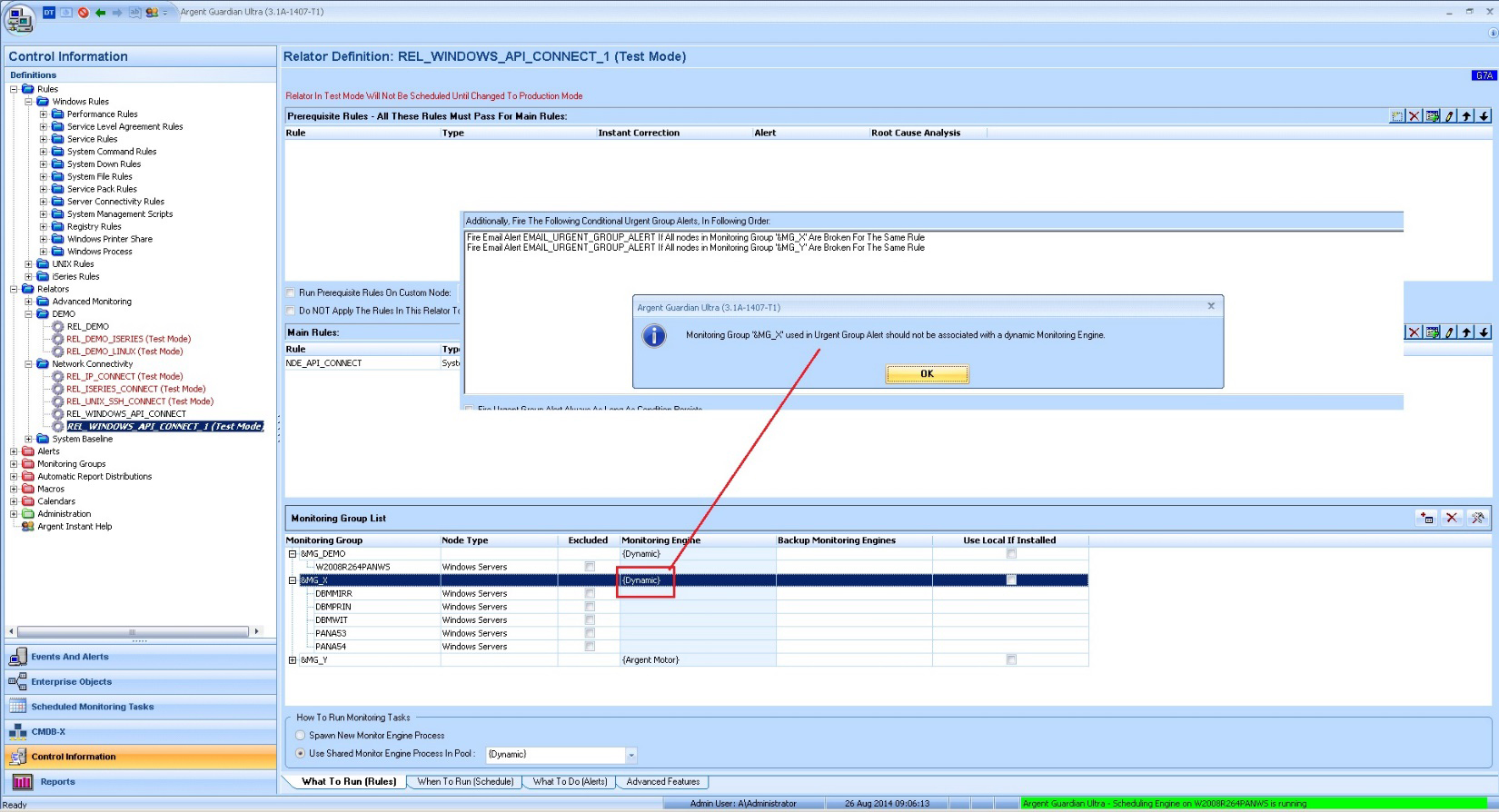
There are two restrictions when defining Urgent Group Alerts:
- The Selected Monitoring Group cannot be associated with Monitoring Engine {dynamic}
The reason behind is that Nodes in the Monitoring Group must be scheduled by one Supervising Engine or Motors at the same location
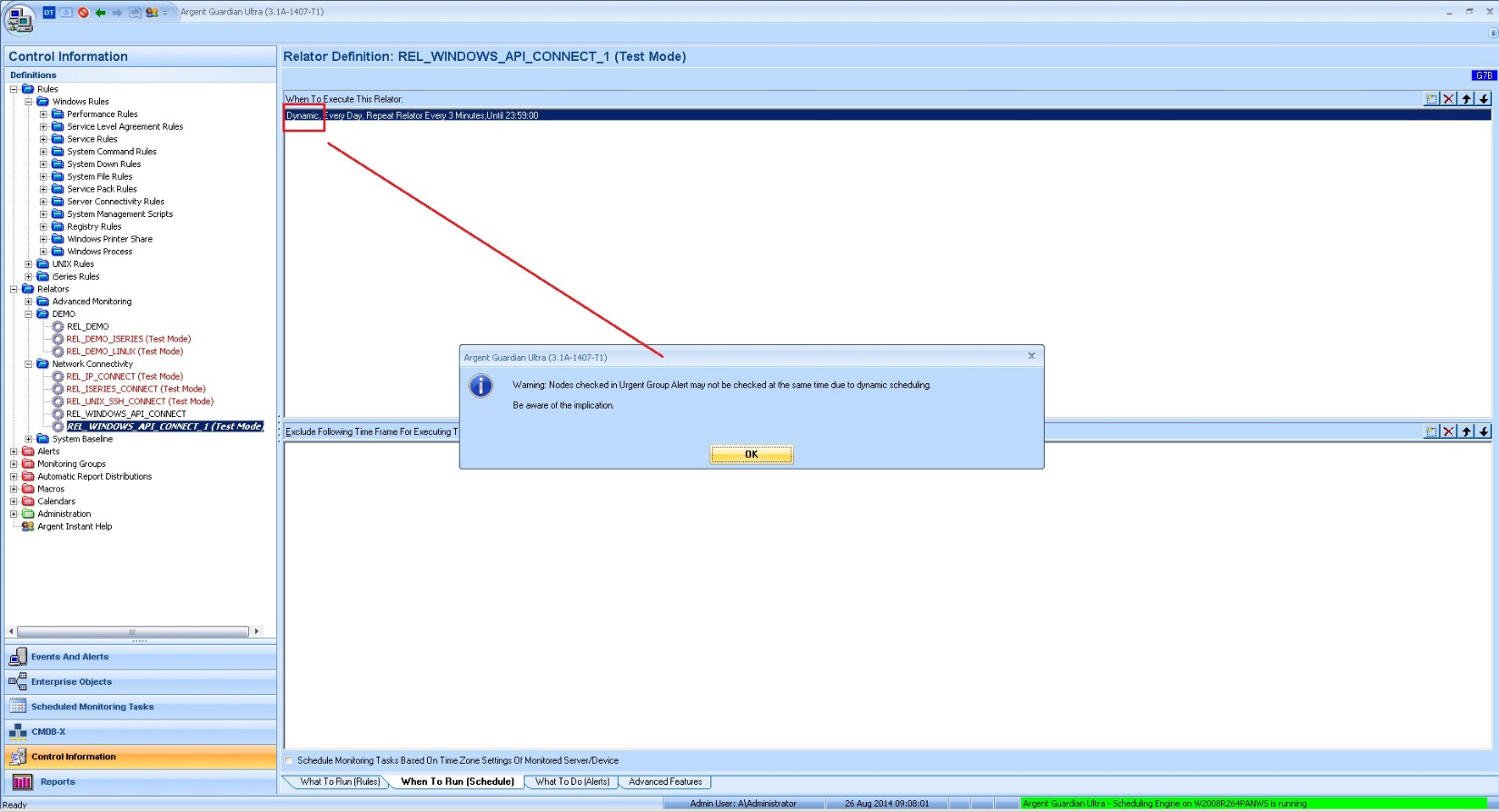
- It is not prohibited but not recommended to use dynamic scheduling
It would be better to find out the condition for all Nodes at similar time
Technical Background
A Relator can have one or multiple Monitoring Groups to monitor
The schedule of Relator defines the interval of Relator executions
Each interval can be considered as a batch to run Rules for the monitored server/devices
The basic idea of Urgent Group Alert is to check the result of Relator in each batch; if a Rule is broken ALL Nodes in the selected Monitoring Group, fire Events for the individual Nodes, then fire the conditional Urgent Group Alert
To understand Urgent Group Alert, customer should carefully read following technical details:
- An Urgent Group Alert is simply an alert that tells customer that a serious condition has happened
There are Argent Console Events for individual Nodes, but no such an Event for Urgent Group Alert
Customer does not need to answer the correspondent Event on Argent Console (A1x)
Instead, he should read the Events of individual Nodes for details
- Urgent Group Alert is normally only fired after Events for individual server/device are fired
For example, Monitoring Group ‘&MG_X‘ includes server A, B and C
In batch 1, A and B are found down and Events are fired
Urgent Group Alert is not fired because C is still up
In batch 2, C is found down and an Event is fired
In batch 3, A, B and C are still down
This default behavior is useful to prevent alert flooding as it can take a while to correct the condition
For extremely critical condition, if customer does not mind to be alerted repetitively, he can override the behavior by checking following option in Relator setting:

When this option is checked, an Urgent Group Alert is fired for each batch as long as all Nodes are still down and no matter if individual Events are fired
- Customer may want Urgent Group Alert to be fired repetitively but find it is too much especially when Relator runs with very short interval
This is especially true for connectivity test using SLA or System Down Rules
To limit the alerts, customer can use following option in Relator setting:
- If some Nodes in the Monitoring Group are suspended, in maintenance mode, excluded in Relator or not licensed, they are not counted when determining if the Urgent Group Alert should be fired
Take previous example, if A and B are down, C is up, but C is in maintenance mode, an Urgent Group Alert will be fired as C is not counted

It is quite straightforward to debug or analyze Urgent Group Alerts
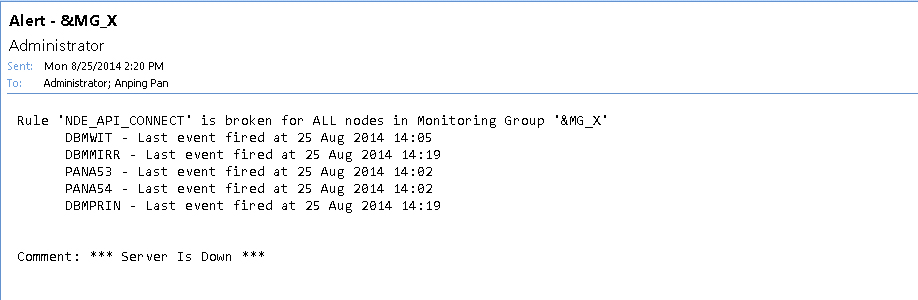
When an Urgent Group Alert is fired, it contains list of Events fired for the individual Nodes
It explains why the Urgent Group Alert is fired. Following is an Urgent Group Alert example:
If an Urgent Group Alert is not fired, Argent AT service log also contains detail explaining the logic. For example:
25 Aug 2014 14:02:32.890 W2008R264PANWS A\Administrator NOT FIRING Urgent Group Alert for Monitoring Group ‘&MG_X‘ in Relator ‘REL_WINDOWS_API_CONNECT‘
Reason: Rule ‘NDE_API_CONNECT‘ has not found broken for Node ‘DBMWIT‘ in current batch
Resolution
Upgrade to Argent Advanced Technology 3.1A-1410-A or later