KBI 311132 Use High Frequency SLA Rule
Version
Argent Advanced Technology all versions
Date
Friday, 19 Dec 2014
Summary
Argent AT SLA Rule checks server/device accessibility by simple ICMP Ping
-
It is the same as the TCP/IP Ping in System Down Rule if default option is used
Argent AT Engine pings the target IP with the default timeout and retry count specified in Licensed Node Properties
-
The option ‘Run Lightweight SLA Checking With Interval Of xxxx Seconds’ is used to implement High Frequency SLA Checking
Normally Rules are executed in the interval specified in Relator
Argent AT Relator is typically scheduled as running once every one or a few minutes
Customer may want to find out down nodes sooner than minutes
High Frequency SLA Checking can be used
The Rule is submitted to Monitoring Engine just like other Rules
However, instead of returning immediately after single execution, the High Frequency SLA Rule will be executed multiple times with the interval specified in the Rule
It returns if the target node is found down, or Relator interval is used up
As a result, in the eye of Supervising Engine, the Relator is executed with interval specified in Relator; in the eye of end user, SLA Rule is executed consecutively with interval specified in the Rule, which is generally a few to 30 seconds, much shorter than the Relator interval
-
The option ‘If TCP/IP Ping Failed, Wait and Check Again’ can be used to more adaptive recheck
If using System Down Rule, customer usually uses the option ‘Post Event Only After Rule Is Broken xxx Times’ to achieve similar
The advantages of the option in SLA Rule include:
- Lighter resource usage
- Faster response within seconds instead of full Relator interval for the double check
- Adaptive timeout To get faster response, the default time out is usually shorter than 10 seconds
- When doing the double check, customer may want to use a longer timeout to be sure
- The longer timeout can be specified in the SLA Rule
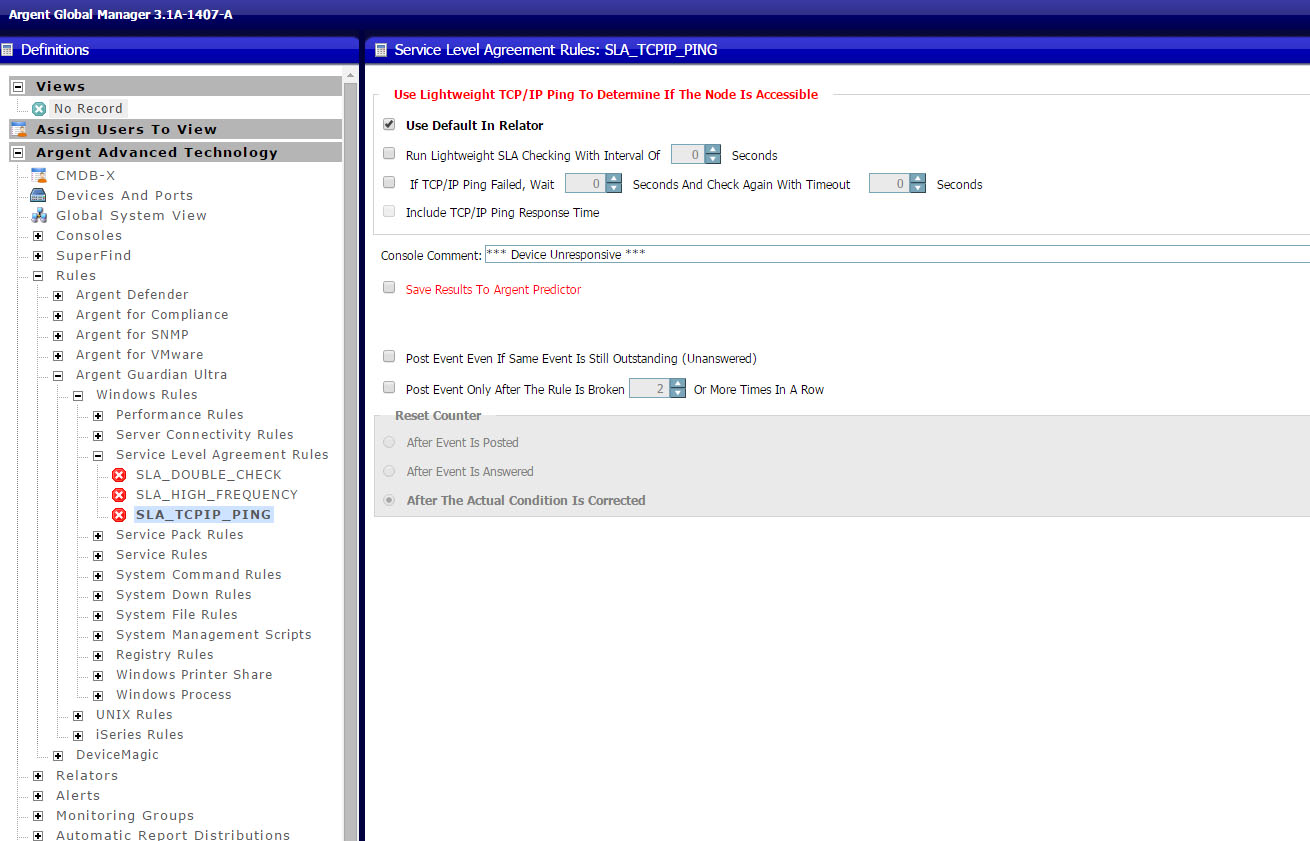
Note: The double check is only done once for the single execution of SLA Rule
It can be combined with the option ‘Post Event Only After Rule Is Broken xxx Times’ to do additional double checks
Technical Background
The main reason to use SLA Rule instead of System Down Rule is the advantage of being lightweight with High Frequency Checking
Argent AT Engine runs Rules using Work Order (WO) files
If System Down Rule is scheduled to run once every 10 seconds against 1,000 server/devices, the I/O burden can easily exceeds the system limit
Using Lightweight High Frequency SLA Rule can handle this elegantly
On the other hand, SLA Rule only does ICMP Ping
When customer needs to check up/down status of Windows Network, WMI, Remote Desktop service etc, ‘System Down Rule’ should be used
To summarize:
- If doing simple one time ping for up/down status, SLA Rule and System Down Rule are equivalent
- If doing ping checks multiple ping checks per minute, use SLA Rule with ‘High Frequency SLA Checking’ option turned ON
- If doing system up/down check other than simple ICMP ping, use ‘System Down Rule’
Resolution
N/A